Geek Software of the Week: FreeOCR!
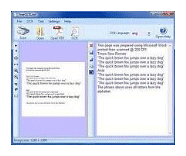 Every so often I do a GSotW that is just TOO good to be true! This is one of them! I used to have an OCR (Optical Character Recognition) application called “Omnipage” that was VERY expensive, but worked very well. It was version 12. The latest version for that product is now version 17. But upgrading was going to be EXPENSIVE! So, as usual, I looked for a free, and/or Open Source version! WOW! Did I find a gem! It is TOTALLY FREE, yet works great, is easy to use, and will even do OCR directly from PDFs without printing the document and then scanning it on my scanner! ZOWIE! This rocks!
Every so often I do a GSotW that is just TOO good to be true! This is one of them! I used to have an OCR (Optical Character Recognition) application called “Omnipage” that was VERY expensive, but worked very well. It was version 12. The latest version for that product is now version 17. But upgrading was going to be EXPENSIVE! So, as usual, I looked for a free, and/or Open Source version! WOW! Did I find a gem! It is TOTALLY FREE, yet works great, is easy to use, and will even do OCR directly from PDFs without printing the document and then scanning it on my scanner! ZOWIE! This rocks!
“FreeOCR is a Windows OCR program including the Windows compiled Tesseract free ocr engine. It includes a Windows installer and It is very simple to use and supports multi-page tiff’s, fax documents as well as most image types including compressed Tiff’s which the Tesseract engine on its own cannot read .It now has Twain scanning. It can also open PDF’s Free OCR uses the Tesseract OCR engine (see below)
Tesseract – The Tesseract free OCR engine is an open source product released by Google. It was developed at Hewlett Packard Laboratories between 1985 and 1995. In 1995 it was one of the top 3 performers at the OCR accuracy contest organized by University of Nevada in Las Vegas. The Tesseract engine source code is now maintained by Google.”